
fable 5 就是 mythos,在 Anthropic 开放使用后快速使用了四天,在我之前的几个个人实验项目上,大概用了 1.5B token。
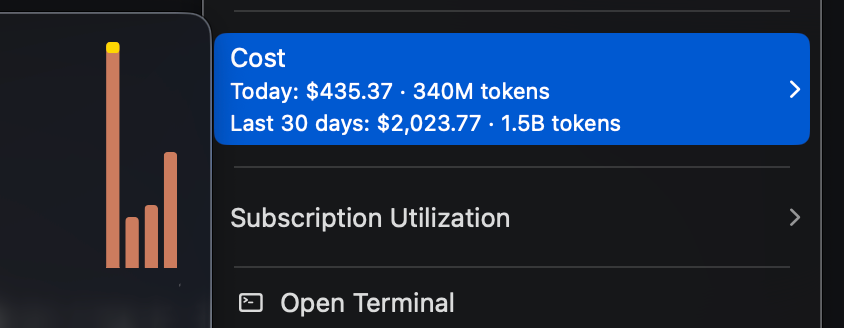
Anthropic 这么着急发布这个新模型应该主要还是因为 opus 4.7 和 opus 4.8 太拉垮了,4.8 更是直接到了不说人话的地步:

看着输出中文,实际上不知道在说什么,甚至都不像 gpt 之前那样一看就能看出来是出自国内某家大厂的黑话,着实离谱。
从 opus 4.7 开始,A 家公开的模型就一直落后 GPT 5.5,从写代码到 debug 全面落后,我们内部的前端 debug 实验,e2e 测试生成都发现 opus 在简单的问题上会频繁犯错,反复浪费 token。这一点,和 data curve 的 deepswe 的结论大体上是一致的:
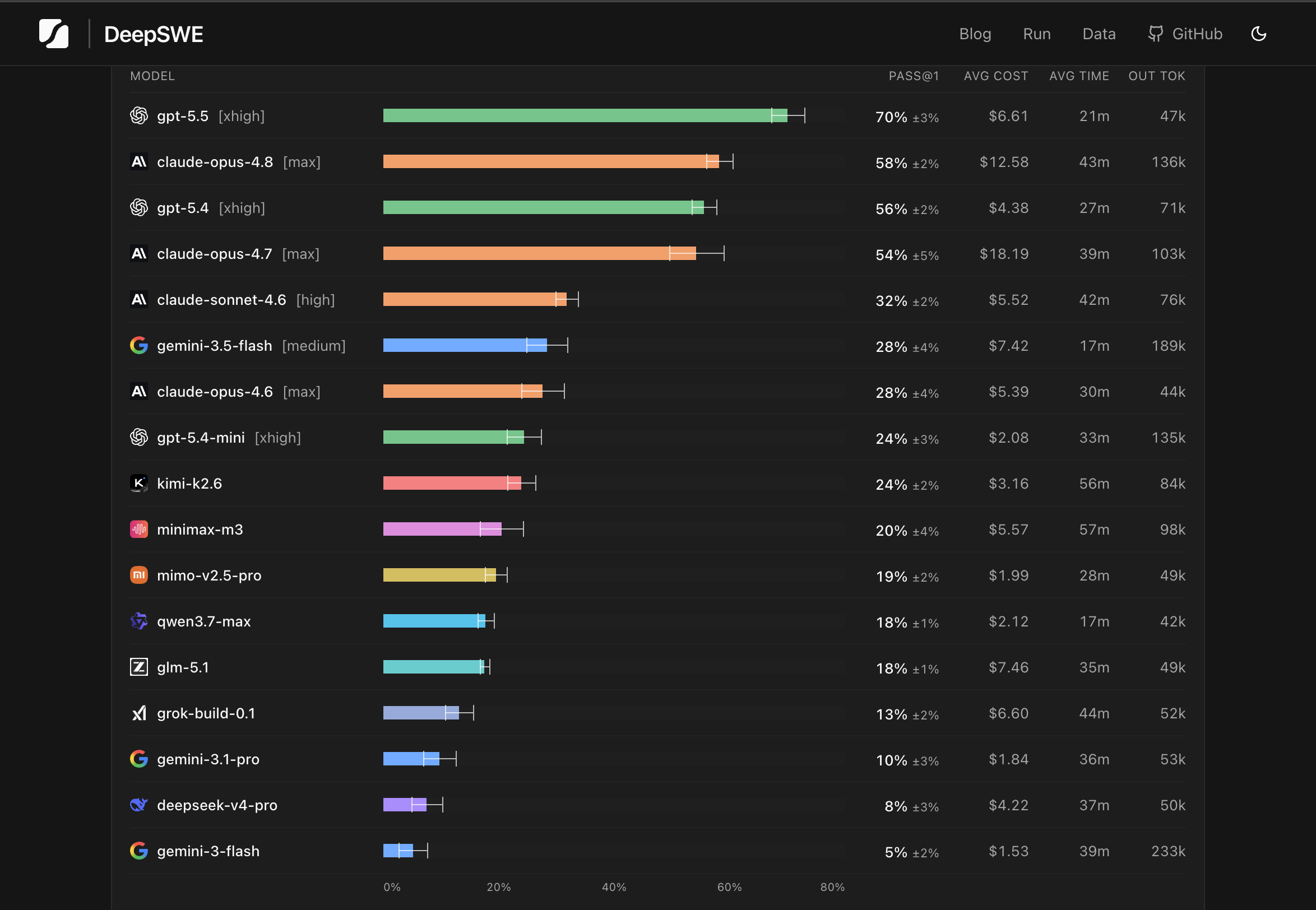
但是 claude code 几乎领先了一年,大多数人还是先入为主,觉得好用,国内的自媒体也不太懂,基本就是互相复读没什么价值的信息。
实际上从 openai 把 sora 关了,又挖了一波人去改进 codex 桌面版之后,codex 就比 cc 好用多了。
当然软件体验好归好,不代表所有场景都比 opus 好,比如我早期分享的,openai 没有 anthropic 那么不要脸,几乎有点名气的书都被训练在了模型内部。。。另外一个比较发现是 opus 在没有提供太多代码规范的指引的前提下,默认写出来的代码的“审美”还可以,会适当地加注释。还是书读太多了,默认就有比较好的写代码范式,这一点上 gpt 还是稍微差一点,你需要在 agent.md 里告诉他尽量要稍微多写一些注释,并且显式地告诉 agent 你自己的代码和架构审美。
除了写代码以外,比较重要的场景是 debug,前段时间我做的 e2e 的 case 生成流程,需要 AI 自主探索页面交互,然后按照交互来生成一些 playwright 的脚本,再生成我的 e2e 测试用例。
这个流程很容易体现出 opus 的短板,比如我们公司的主流程页面,第一次登陆会退出大量的 modal 对话框,要求绑定 2fa 的,user journey 的一路点击 next 的,以及投资者调查的问卷 modal 的,我猜应该之前前端也没什么规范,所以什么形式的 modal 都有。甚至连关闭按钮都可能是个 <a> 元素,<div> 元素,或者是 <button> 元素,这种没有规范的场景,能明显地感受到 opus 的无力,就为了关四五个弹出窗口,opus 努力了一两个小时还在不停地尝试,直到把我的耐心耗尽,换成 gpt,很快就解决了。综合来看,结合 browser use 的 opus 非常非常差,特别是 debug。
fable 出来就完全不一样了,相比 GPT 5.5 没有特别明显的短板,fable 是实现目标的时候,会顺手帮你发现很多存量系统的问题,并且帮你转换成新的任务。(当时忘了截图了)
再和去年的 opus 4.5 时刻相比一下,fable 又上了一个新台阶,四天的密集使用现在让我觉得 fable 大部分的输出,都没什么大问题。
比如我让 fable 把我很喜欢的一个社区项目 heaven studio 从一个 unity 项目移植成了 Go 的 ebiten 游戏:
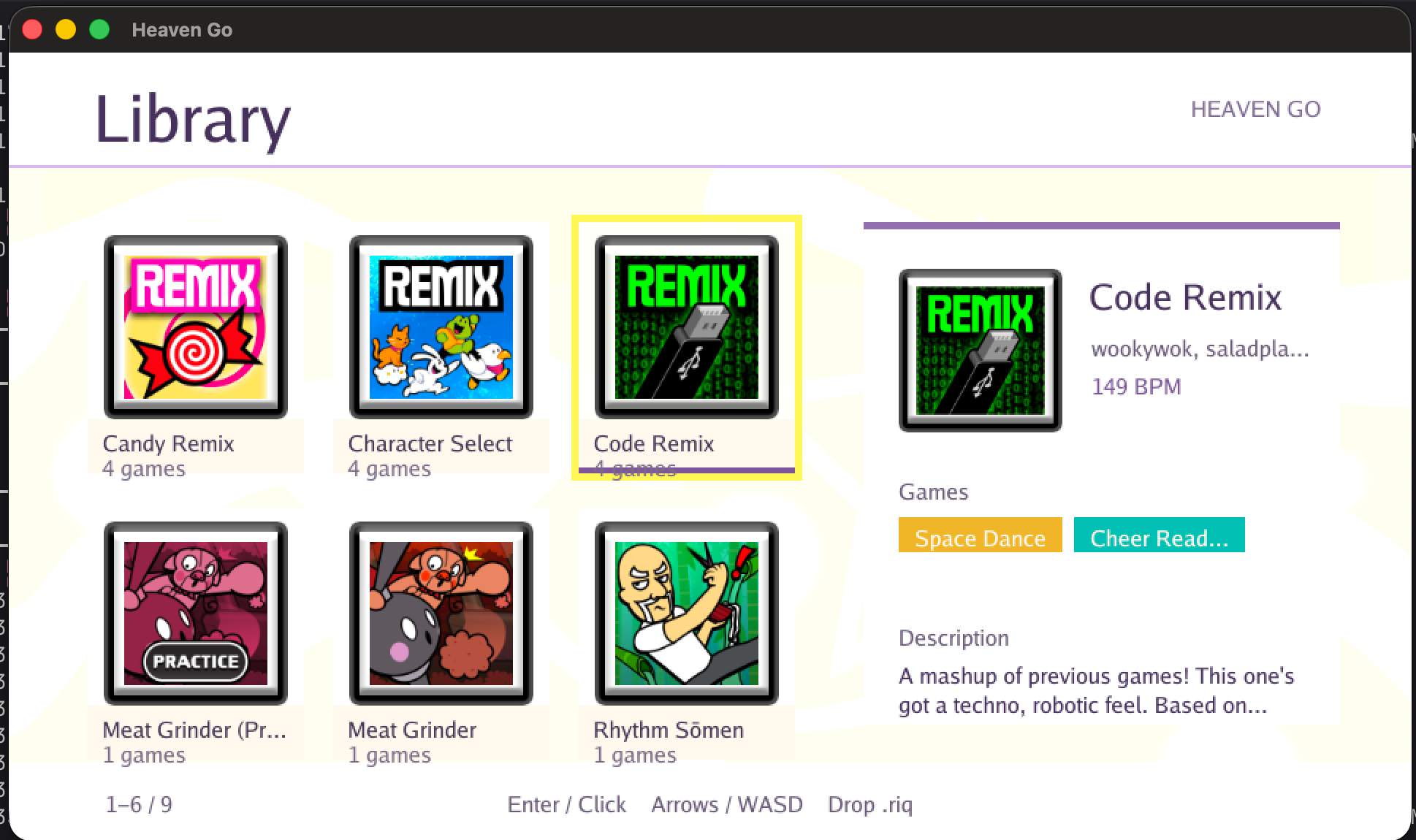


unity 引擎里提供了大量基础设施在移植到 ebiten 的时候是肯定没有的(比如各种曲线和运动逻辑),这需要 Agent 能理解原来的引擎的能力,并且能纯粹通过自己的推演(或者 unity 的源码?)翻译成对应的 Go 代码。
这也让我理解了为什么像 bun 这样的项目,敢在 6 天内让 mythos 来重写 100w 行代码,这放在之前的模型(即使是 gpt 5.5)是不行的。
我也反思了一下从去年到今年我个人的观点变化,最开始 openai 讲 harness 的时候,我觉得他们是在吹牛逼的,因为 openai 讲了半天 harness,实际上最终没有一个交付的项目,而只开源了 symphony 这个平台。
回过头来看,当时我这个判断是有问题的,在 gpt 5.5 的模型能力前提下,适当的上下文工程,完善的测试覆盖率,对 AI 友好的 cli/mcp 基建,和一个任务管理的 symphony 平台(开源不友好,不过你可以去用 multica),内部无限 token 跑 fuzz test 和 chaos test,再加上 human in the loop 的关键环境 review,从理论上几个月交付一个大项目没什么问题。实际上,现在工具类的大项目交付甚至已经变成以周计算了。
而模型厂坏就坏在他们自己内部用的是下一代模型和无限 token,这些方法论都是基于下一代模型给出的,而我在外部模型的能力基础上去做方法论评估,认为他们是在吹牛逼也是合乎逻辑的,两者的前提完全不一样。
之后再看到 openai 和 anthropic 官方的工程方法文章,要更多想一下他们的前提,而不是直接断定这些是 PR 目的。
今年开始,模型厂的普遍观点是未来人不一定非得在 loop 里了,像 bun 这样大刀阔斧一周从 zig 全重写到 rust 最后还能成功,这也说明技术决策的错误不像以前想的那样不可承受了。即使已经经过了几年的代码累积,只要你的代码测试覆盖比较完善,那重写根本就不是什么大事。
为什么 bun、shopify、stripe 这些公司可以,你国内公司就不行
结论非常简单,前提不一样。国内公司,包括那几家大的,历来不重视软件工程。
直到现在,bat 内部的很多核心系统的测试还是一坨翔。这么多年,这些所谓的大公司积累出来的最重要的经验就是阿里所谓的三板斧,可灰度,可监控,可回滚。看起来很科学,核心其实就是公司内不同职能互相兜底(研发给产品兜底,QA 给研发兜底),对外拿用户当测试(通过小流量观察问题,有问题就回滚)。
很多互联网产品的功能生命周期又没那么长,这么跑了十多年也没碰到什么问题。你要认真讲软件架构,很多公司连基本的软件架构文化都没有,只要不是数据库,大家都想自己造。
现在看到硅谷好像 AI native 落地还不错,技术一把手们都 FOMO 了,也都要 All in AI。也不照照镜子看看自己公司的软件研发工作流是什么德性。
以前大家互相兜底,研发写代码阶段,边写还能边想,现在写代码让 AI 写了,一天几万行,看都看不过来,怎么可能把各种 corner case 都想清楚?
硅谷有些公司没有 QA,比如 shopify,运转顺利。这不代表 QA 的那些工作不需要人做,他们写单测是让研发自己写,白盒测试研发和产品共同承担,e2e 测试甚至是让公司的 SRE 团队来承担。
我们再说 stripe,stripe 本身是个支付公司,他们的核心产品是 SDK 和支付 API,这些东西和普通的 C 端业务是不一样的,具有非常高的确定性,并且 stripe 的测试覆盖非常非常高,这个从他们之前的分享也能看出来。
但是拿 stripe 的案例来宣传,国内这些公司的一把手就 FOMO 的不行了,觉得 stripe 可以一周 merge 1000+ 个 PR,那我们也应该可以!
你看看自己主流程系统测试覆盖率吧,别天天做梦了,让普通研发在大公司的存量系统里写代码,都得写一行代码问一小时背景,你让 AI 来搞,AI 也不是造物主。
mythos/fable 之后
说回 fable,尽管因为外力介入,fable 暂时无法使用了,但这个外力不会是永久。
我们需要尽快思考组织和个人的出路,opus 能做到 6 成以上的代码和任务可靠率,fable 至少能达成 8 成以上的输出可靠,那对于唯命是从的初中级脑力劳动者来说,未来的生存一定是地狱难度。
在 fable 之后,可预见的将来(也许就是明年了),国产模型也会逐渐达到 fable 的能力,那一刻就是国内的公司可以把普通员工当敝履的时候。
如果你没有准备好,那么你一定会非常被动。
If you don't keep moving, you'll quickly fall behind
Beijing