2023.12.11-2023.12.17每周文章分享标题: FACMAC: Factored Multi-Agent Centralised Policy Gradients会议: Advances 2023-12-16 08:58:50 Author: 网络与安全实验室(查看原文) 阅读量:48 收藏
2023.12.11-2023.12.17
每周文章分享
标题: FACMAC: Factored Multi-Agent Centralised Policy Gradients
会议: Advances in Neural Information Processing Systems (NIPS), 2021, 34: 12208-12221.
作者: Bei Peng, Tabish Rashid, Christian A.Schroeder de Witt, Pierre-Alexandre Kamienny, Philip H. S. Torr, Wendelin Bohmer, Shimon Whiteson.
分享人: 河海大学——朱胜超
研究背景
在集中式训练分布式执行(centralized training with decentralised execution)框架下,有两类经典的多智能体强化学习算法,第一类基于值函数分解(value decomposition),代表算法有VDN、QMIX等,本文简称为VD类算法;第二类基于集中式critic,代表算法有MADDPG等,本文简称为MADDPG算法。由于VD类算法以DQN算法为基础算法,所以一般用于离散动作空间,代表任务有SMAC(StarCraft Multi-Agent Challenge);而MADDPG类算法以DDPG算法作为基础算法,所以一般用于连续动作空间,代表任务有MPE(multi-agent particle environments)。总结来说,VD类算法和MADDPG类算法的不同体现在两个方面:
(1)基础算法不同,VD类基于DQN,MADDPG类基于DDPG;
(2)多智能体协同方式不同,VD类基于值函数分解,MADDPG类基于集中式critic。
由于VD类算法和MADDPG类算法所适用的环境不同,直接将两者放在一起比较并不容易。有一些论文用SMAC或者离散动作空间的MPE对VD类算法与使用了gumbel-softmax的MADDPG类算法进行比较,结果表明QMIX比MADDPG性能好,但这很难表明到底是因为MADDPG不适用于离散动作空间,还是因为值函数分解的协同方式比集中式critic更优。
基于此,作者将值函数分解引入MADDPG中,通过大量实验验证性能。
关键技术
本文提出一种对MADDPG的改进算法FACMAC,将QMIX等论文的值分解思想引入到actor-critic算法的critic中,对critic的Q值进行分解,与QMIX等论文不同的是,这里的分解没有单调性约束。同时,FACMAC使用了一个集中式的策略梯度估计器,计算梯度时对所有智能体的策略求梯度,而不是对单个智能体的策略求梯度。实验部分在连续环境MPE、Multi-agent MuJoCo,以及离散环境SMAC下进行实验和消融实验,验证了算法的效果。
该方法的创新和贡献如下:
1)将值函数分解引入到actor-critic架构中,使用了一个集中式的策略梯度估计器。
2)在多种任务环境下,对比了MADDPG(基于策略梯度算法的代表)和加入值函数的MADDPG算法,证明了值函数分解的有效性。
算法介绍
在算法介绍部分,首先简单介绍MADDPG、VDN、QMIX,阐述其原理,再去分析作者是如何结合生成了FACMAC算法。
(1)MADDPG
图1 MADDPG算法架构
如图1所示,MADDPG以DDPG算法为基础,每个智能体均需要学习一个critic与一个actor,其中critic接收所有智能体的观测-动作作为输入,而actor则只能以单个智能体的局部观测为输入,输出其动作。由于每个智能体都会单独学习一个Q值,因此每个智能体都能够设计任意属于自己的奖励。MADDPG背后的思想是,如果我们知道所有智能体执行的动作,那么即使每个智能体的策略都在发生变化,整个系统的环境也是平稳变化的。
实际上,MADDPG各个智能体的学习过程可以看做是相互独立的,只是在学习的过程中需要利用其他智能体的观测-动作信息,也就是说在训练过程中进行了观测共享。这样做的好处是,MADDPG可以用在异构智能体的场景中,这里的异构指的是不同智能体的观测空间、动作空间或奖励函数可以不同。但是,由于critic需要接收所有智能体的观测-动作作为输入,其输入会随着智能体数目的增加而增加,存在扩展性问题。并且,为了保证critic输入节点固定,MADDPG中智能体的数目还必须是固定的,不允许智能体数目动态变化。
考虑异构智能体既是MADDPG的优势,同样也使MADDPG存在一些局限。当所有智能体都共用一个系统奖励时,每个智能体所学习的critic实际上是全局critic,评估的是所有智能体的整体观测-动作对的好坏,因此单个智能体无法从中判断自身观测-动作对整个系统的影响,这也就是所谓的信用分配(credit assignment)问题。
(2)VDN/QMIX
图2 VDN结构图
值函数分解可以解决多智能体系统中的信用分配问题,如图2所示,在VDN中,假设对于所有智能体做动作所导致的系统奖励,有一个全局Q网络,单个智能体的动作同样也会对应一个局部Q网络,VDN假设局部Q网络与全局Q网络存在线性关系,即
然后通过总的损失函数进行反向传播即可训练出各个智能体的局部Q网络,而无需为单个智能体设计奖励。可以看出,不同于COMA,VDN是直接为每个智能体学习到了一个局部的Q网络,该局部Q网络可直接用于离散任务中的分布式决策。我们很容易想到,可以将VDN的思想应用在actor-critic框架下,实现连续任务的控制,MAAC就用到了这样的框架。
VDN将所有的局部Q网络加起来去近似整体Q网络,即认为两者之间的关系是简单的求和,但实际上局部Q网络与整体Q网络之间的关系很复杂。另外VDN在学习期间没有利用任何额外的状态信息。为此,QMIX提出用神经网络将局部Q网络与整体Q网络之间的关系拟合成一个单调函数,另外QMIX还在训练过程中额外使用了全局状态信息。
(3)FACMAC
图3 FACMAC结构图
如图3所示,所有智能体一起使用一个集中式的critic,且critic的值可被分解为
Critic网络更新参数的方式仍然使用时序差分的思路。
在FACMAC中,为了对各个智能体的策略进行更新,一种比较直接的方式是类似于MADDPG,利用集中式的critic或值分解之后的局部critic计算单个智能体策略的梯度,但会导致策略进入次优解。因此,作者提出对整个联合动作空间进行集中式更新,也就是说在估计Q值时,根据所有智能体当前的策略采样动作,此时集中式的策略梯度可以计算为
总的来说,FACMAC的改进不大,只是在MADDPG的基础上,使用了值分解的方式拟合Q值,而避免了集中式Q值面临的维度爆炸问题,同时,使用了集中式的策略梯度更新网络。但这种思路以及对比实验都是很有意义的。
实验分析
在仿真部分,作者使用的环境是多智能体强化学习中常用的环境,MPE、MuJoCo、SMAC。
(1)连续任务(MPE/MAMuJoCo)
对比算法:MADDPG、independent DDPG、VDN with CEM(COVDN)、QMIX with CEM(COMIX),CEM指的使用交叉熵的方法近似贪婪的动作选择。
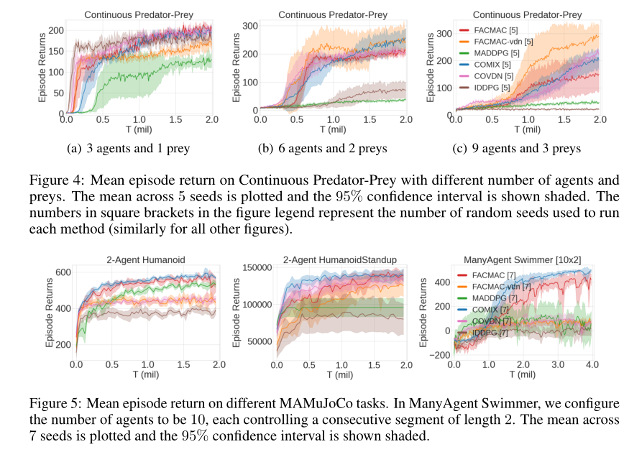
图4 连续任务下的算法对比图
如图4所示,从这些实验结果中,可以肯定的一点是,MADDPG的效果确实不好,特别是当智能体数目增加或任务难度增大时。增加了值函数分解以及集中式策略梯度之后的FACMAC能够明显提升MADDPG的性能。另外,6个实验中有4个实验都是COMIX的性能最好,这充分说明了值函数分解的优势,也就是说,值函数分解本身就是一种非常优秀的算法,甚至不需要利用actor-critic框架,仅仅使用简单的CEM来处理连续任务,也能获得非常好的性能。
(2)离散任务(SMAC)
图5 离散任务下的算法对比图
如图5所示,当智能体数量增加时,MADDPG算法的性能变得很差,整体实验结果如图4中基本一致,但是出现了FACMAC在离散任务中能够达到接近甚至超过QMIX的性能。
(3)消融实验
图6 消融实验(证明集中式策略梯度的优势)
如图6所示,作者进行了消融实验来证明集中式策略梯度的优势,带有CPG的算法代表使用了集中式策略梯度的方法。作者在不同的环境任务下对比了具备和不具备集中式策略梯度方法的FACMAC与MADDPG,实验结果证明,集中式策略梯度算法相比于传统的策略更新,性能上有所提升。
我个人考虑是因为,其考虑了所有智能体在当前策略下进行采样,而传统的方法只有更新网络的智能体如此采样,相比之下,集中式策略梯度考虑了时间上智能体的动作一致性。
总结
本文将值函数分解的思路加入到基于策略梯度的MADDPG算法中,将基于策略梯度和基于值函数分解的两种多智能体强化学习算法结合,提出了FACMAC算法。
相比于提出FACMAC这个算法本身,我个人认为这篇论文更大的意义应该是充分地对比了QMIX与MADDPG两类算法,同时表明了QMIX的优势,实验结果也表明,FACMAC的效果可能还不如直接使用QMIX。
END
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh