每周文章分享2023.05.15-2023.05.21简介标题: Achieving Lightweight and Privacy-Preserving Object Detection for C 2023-5-19 23:59:20 Author: 网络与安全实验室(查看原文) 阅读量:32 收藏
每周文章分享
2023.05.15-2023.05.21
简
介
标题: Achieving Lightweight and Privacy-Preserving Object Detection for Connected Autonomous Vehicles
期刊: IEEE Internet of Things Journal, vol. 10, no. 3, pp. 2314-2329, February 2023.
作者: Renwan Bi, Jinbo Xiong, Youliang Tian, Qi Li, and Kim-Kwang Raymond Choo.
分享人: 河海大学——朱远洋
研究背景
联网自动驾驶汽车(CAV)可以利用车载传感器捕获高清晰度的图像,从而帮助检测周围的物体,提高安全性和效率。边缘计算可以大大降低CAV的计算成本,有助于在有限的网络带宽下分析大量的驾驶数据。同时,它可以通过融合和处理从多个CAV收集到的信息来提高态势感知能力。但是,这些图像可能包含一些敏感信息,比如人脸和车牌,以及车辆的间接位置。如果这些图像被共享给其他车辆或者边缘服务器,就可能泄露物体的隐私。因此,如何在保护物体隐私的同时,实现高效的目标检测,是一个重要的研究问题。
关键技术
本文提出了一种轻量级的深度水下目标检测网络,该网络能够同时学习水下图像的颜色转换和目标检测。该网络的关键技术包括图像颜色转换模块、目标检测模块和联合学习策略。图像颜色转换模块旨在将彩色图像转换为对应的灰度图像,以解决水下颜色吸收的问题,从而提高目标检测性能,并降低计算复杂度。目标检测模块采用了一种基于锚点框和特征金字塔网络(FPN)的单阶段目标检测器,能够有效地处理不同尺度和形状的水下目标。联合学习策略通过共享卷积层和使用多任务损失函数,实现了图像颜色转换和目标检测两个任务之间的互相促进和优化。作者在树莓派平台上实现了该网络,并在公开的水下数据集上与其他先进方法进行了对比实验,结果表明,该网络具有较高的目标检测精度和较低的运行时间。
本文的主要创新和贡献有三个方面:
1)针对电池供电的AUV的应用,本文提出了一个用于水下目标检测的轻型深度模型。依靠多尺度特征学习网络,所提出的深度网络被证明是轻量级的,而不会明显牺牲在Raspberry pi平台上实现的目标检测精度。
2)与最先进的水下目标检测框架不同,本文提出了联合学习图像颜色转换和目标检测的过程,以解决水下颜色失真和散射效应的问题,提高检测性能。
3)基于水下图像的训练样本难以收集的事实,本文提出了生成训练水下图像,以很好地训练所提出的深度目标检测模型。
算法介绍
1.系统概述
A.系统模型
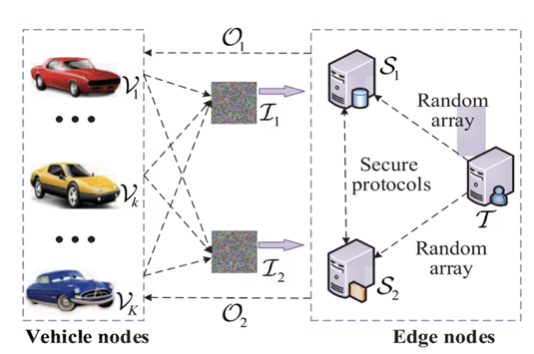
在系统模型中,有三个主要实体:1)K个CAV {V1, …, Vk, …, VK};2)两个边缘节点{S1, S2};以及3)一个轻量级第三方服务器T,如图1所示。
图1 P2OD框架的系统模型
1)每个CAV Vk (k∈{1,...,K})捕获图像并将其随机分割成两个图像分量。这些图像分量被聚合成I1和I2,并分别被发送到S1和S2。每幅图像都保留了发送车辆的标记。然后,Vk等待来自S1和S2的响应,并且仅使用共享O1和O2的相加来恢复实际检测结果。
2)S1和S2负责安全地检测两个随机图像分量上的对象。当接收到I1和I2时,S1和S2根据网络顺序协同执行设计的安全计算协议,并获得对象分类和位置分量。然后,S1和S2将带有不同标记的O1和O2反馈给对应的Vk。显然,在S1和S2的辅助下,CAV可以通过添加分量来获得真实的检测结果。
3)可信的T负责离线生成并为S1和S2提供足够的随机数,以保证安全计算协议的执行。由于生成操作与Si的计算是独立的,T可以在空闲时间将它们分配到Si中存储和使用。这些随机数是从大小为2l的整数环Z中统一选择的(l为输入值的位宽),因此它们可以隐藏秘密值,这些秘密值对于潜在的对手来说在计算上是无法区分的。
B.安全模型
神经网络模型的参数对Si (i=1, 2)是私有的,Vk无法知道;Si提取的原始图像、特征分量以及最终的目标检测结果都是Vk私有的,Si无法知道。在半信任模型中,T仅离线生成一些随机数,不参与S1和S2之间的在线交互,因此T不影响该模型的安全性。S1和S2被认为是诚实但好奇(honest-but-curious,HbC)服务器,它们严格遵循协议步骤,并期望从已知信息推断出真正的隐私价值。假设S1和S2是非合谋的,它们可以由两个竞争的服务提供商托管。此外,Vk是受信任的,不会恶意失去连接或干扰通信。在计算过程中,如果真实隐私信息不能被Si和概率多项式时间(PPT)对手A截获,则认为所提出的模型是安全的。假设A具有以下能力:①A最多可以窃听CAV发送给一台服务器的信息,或者由一台服务器反馈给CAV的信息;②A最多可以破坏S1和S2中的一个并获取其信息。
C.设计目标
本研究的目标是为CAV系统设计一个P2OD框架,关键是如何设计有效的安全计算协议并实现随机图像分量上的轻量级物体检测。设计目标的细节如下:
1)安全性:隐私关注的是整个过程中的真实图像像素和特征值。由于这些私有值在边缘服务器上始终以秘密分量的形式存在,且S1和S2不能恶意串通,因此对象检测结果受到保护。A在攻击约束下也无法获得有意义的信息。
2)正确性:提出的P2OD框架的目标是在正确性方面达到与原始Faster R-CNN模型近似的目标检测效果,确保设计的安全计算协议与原有特征之间的计算误差可以忽略不计。
3)轻量级:安全计算协议的设计遵循S1和S2之间的计算成本和通信轮数最小化的原则。本文试图缩小P2OD框架与Faster R-CNN模型的计算开销差异。
2.安全计算协议的设计
A.安全转换协议
由于非线性函数不能直接分成两份,但可以转化为加法和乘法的组合形式(或分量)。因此,开发了一种加性共享和乘性共享之间的安全转换。利用基本的因式分解特性,非线性函数的共享可以在没有多项式迭代的情况下实现。Protocol 1和Protocol 2分别说明了乘性共享到加性共享安全转换(STMA)协议和加性共享到乘性共享安全转换STAM协议的构造。在N个参与者之间加性共享隐私值u。每个参与者拥有一个分量[[u]]i,所有分量之间的相加可以重构u。
B.基本计算的安全协议
利用STMA和STAM协议,设计了一些安全的乘法、除法、指数和比较等基本计算协议。安全乘法(SMul)、安全除法(SDiv)和安全指数(SExp)协议的构造分别在Protocol 3-5中说明。考虑到乘性共享和加性共享之间的自由切换,可以设计SMul和SDiv协议。S1和S2协同计算,得到最后的结果[[f]]1和[[f]]2,分别满足[[f]]1 + [[f]]2 = ([[u]]1 + [[u]]2)·([[v]]1 + [[v]]2)和[[f]]1 + [[f]]2 = ([[u]]1 + [[u]]2) / ([[v]]1 + [[v]]2)。另外,SExp协议的目标是计算[[f]]1 +[[f]]2 = exp([[u]]1+[[u]]2)。指数运算的结果随着正数的增加而迅速增加。因此,需要缩小输入分量的范围,以避免计算溢出,如Protocol 5的第1-5行所示。特别是通过STMA和STAM协议,可以安全地实现非线性除法和指数计算,而不需要额外的多项式迭代,只需要几轮通信。
比较计算可以简化为提取最高有效位(MSB)的问题。u的MSB定义如公式(1)所示。通过一些算术运算设计了一个高效安全的比较(SComp)协议。MSB可以通过计算sign(⋅)函数求解,表达式如(2)所示
给定输入分量[[u]]i和[[v]]i (i = 1, 2),使u = [[u]]1 +[[u]]2和v = [[v]]1 +[[v]]2,S1和S2协同计算MSB分量[[f]]1和[[f]]2,使f = [[f]]1 +[[f]]2,如Protocol 6所示。若f = 0,则u ≥ v;否则(f = 1),u < v。
3.P2OD框架的构建
A.P2OD框架概述
图2展示了P2OD框架的概况。原始图像被随机分割成两个分量,分别上传到S1和S2。然后,S1和S2协同执行一系列安全计算协议实现P2OD框架。使用VGG16提取映射到整幅图像的高层特征;为了保证图像的隐私性,S1和S2可以在局部计算随机图像分量上的线性Conv和FC运算。此外,设计了SRU和SMP协议。RPN用于检测图像中的目标边界框。P2OD框架采用SAT协议将锚框转换为目标边界框,采用SNMS协议消除冗余边界框。在安全对象特征匹配阶段,ROI-Pooling层调用SRP协议将对象与对应的特征图进行匹配。最后阶段对提取的物体进行安全分类并回归边界框。采用SSM协议对物体类别得分进行安全归一化处理。
图2 P2OD框架的概述
B.安全的图像特征提取
安全特征提取是P2OD框架的关键步骤。S1和S2协同执行Conv、ReLU和最大池化层操作。对于Conv层,给出两个输入分量[[x]]1和[[x]]2,使真实的特征映射x = [[x]]1 + [[x]]2。使用核权重w和偏差b,S1计算[[y]]1 = w ⊗ [[x]]1 + b, S2计算[[y]]2 = w ⊗ [[x]]2,其中⊗表示卷积操作。显然,真正的卷积结果y等于[[y]]1和[[y]]2的和。ReLU函数求解max{x, 0},需要安全地比较每个输入特征x和0之间的关系。其数学表达式如下
SComp协议与输入的位宽无关,只需要几轮通信。在公式(3)基础上,ReLU操作可以在Protocol 7中安全地执行。SRU协议不仅保护了输出特征的隐私,也隐藏了激活特征的分布。
Max-pooling将特征图分为几个pooling子区域,并将每个子区域的最大特征作为输出。SMP协议被设计用来安全地实现最大集合操作,如Protocol 8所示。S1和S2依次执行SComp和SMul协议n2-1次。最终,S1和S2可以得到这个集合子区域的最大特征分量[[y]]1和[[y]]2。
C.安全的物体边界检测
连续Conv模块提取的特征意味着物体的位置信息。在检测物体边界框之前,通过使用两个Conv层来获得在某一位置覆盖物体的概率以及与真实边界框相适应的偏移参数。RPN的目标是使用一些具有不同比例和比率的锚定框来定位物体。为了保护物体位置的隐私(即偏移参数的隐私性),设计了SAT协议来克服这个问题,如Protocol 9所示。给定公共锚框A和私有偏移参数分量[[D]]i,SAT协议获得预测物体边界框B的分量[[B]]1和[[B]]2,使B=[[B]]1+[[B]]2。一些预测的边界框是不规则的,需要进行额外的剪裁操作来保留图像边界内的部分。中间结果是以分量的形式存在的,Si无法获得真实的边界框坐标。
为了在不影响准确率的同时提高检测效率,Faster R-CNN采用非极大值抑制(NMS)方法消除冗余的低分数边界框。为了保护NMS操作时的对象位置隐私,设计了SNMS协议,安全地挑选出一批低冗余、高检测分数的边界框,如Protocol 10所示。给定物体边界框分量[[U]]1和[[U]]2,以及相应分数的分量,SNMS协议使用公共相似度阈值η获得低冗余边界框分量Vi。最后,Si可得到保留的索引,并得到相应的边界框分量。
D.安全对象特征匹配
ROI-Pooling层负责将物体边框与相应的图像特征图进行匹配,如图3所示。对象特征图的计算会泄露对象的位置信息。为了克服这个问题,设计了SRP协议,如Protocol 11所示。对于每个物体边界框分量,以及图像的特征图分量[[Ψ]]1和[[Ψ]]2,SRP协议的目标是获得每个物体的特征图分量[[T]]1和[[T]]2。
图3 ROI-Pooling实例
E.安全对象分类和回归
在收到共享的对象特征后,该阶段对对象进行分类,并对边界框进行回归。为了保证中间计算结果的隐私性,S1和S2合作执行FC、ReLU和Softmax层的具体操作。给定每个物体的分类分数向量,Softmax函数使用指数归一化模式将其归一化到区间[0, 1],并得到分类概率向量,如下所示
一个额外的max(⋅)函数可能会导致大量的开销,特别是在密文计算方面。此外,安全计算过程中不可避免地会引入大的随机数。因此,SExp协议被设计为缩小指数计算的输入分量范围(见Protocol 5)。在此基础上,进一步设计支持多元素情况的SSM协议,以保护Softmax计算中的分类隐私。如Protocol 12所示,S1和S2调用SDiv和SExp协议来安全地实现Softmax函数的指数运算和除法运算。
实验结果分析
1.拟议的安全协议的性能
影响运行时间和误差的因素分别是输入数量和输入范围。从图4(a)和(b)来看,SRU和SMP协议的运行时间随着特征数的增加而线性增加。SComp协议是上述协议的核心。SComp协议完全由算术电路构成,不需要布尔电路或环之间的转换。在明文环境下,SRU和SMP协议的运行时间低于SecureNN和FAlCON,略高于Faster R-CNN。从图4(c)-(f)可以看出,SAT、SNMS、SRP和SSM协议的运行时间与特征数量或边界框数量具有相似的线性关系。与原始的Faster R-CNN相比,这些提出的协议具有类似的增长率,随着输入数量的增加而变化。从图4(g)和(h)来看,SRU、SMP、SAT、SRP和SSM协议的计算误差随着输入值的增加而缓慢增加。值得一提的是,SNMS协议的误差等于0,随着边界框值的变化而变化。
图4 拟议的安全计算协议的效率和效果
2.P2OD框架的性能
P2OD框架包括安全图像特征提取、安全对象边界框检测、安全对象特征匹配以及安全对象分类和回归阶段。上述操作的性能取决于基础安全协议的效果。表1说明了P2OD框架中四个阶段的计算成本和通信开销。在第三阶段,S1和S2花费大量的计算和通信开销来实现SRP协议,特别是泛化对象的位置。
表1 在Raspberry Pi 3 B+上的定量性能评估
为了验证P2OD框架的正确性和安全性,从测试的KITTI数据集中随机选择了几幅图像来进行物体检测,如图5所示。这里,设定l=8。图6显示了原始图像(I)和秘密共享图像(I1和I2)的像素直方图。从图6(a)来看,I的高频灰/像素值集中在一个特定的区域(即从0到100)。从图6(b)和(c)来看,I1和I2的灰度值在0到255之间均匀分布。这种现象意味着I的统计分布特征被随机的像素级共享所隐藏。更重要的是,I可以通过简单地添加I1和I2来恢复(图6(d)),这意味着可计算性和可逆性特性。从物体检测的直观效果来看,S1和S2不能获得任何物体的类别和形状信息,见图5(b)和(c)。
图5 P2OD框架和Faster R-CNN的检测结果比较
图6 图5中第四幅图像的像素频率直方图
此外,模型精度也是衡量P2OD框架的一个重要方面。从图7(a)中可以看出,P2OD框架和Faster R-CNN提取的特征图和检测到的边界框的误差分别在10-16和10-10左右。分类和回归的误差分别在10-12和10-14以内。P2OD框架不受Faster R-CNN固有检测效果的干扰。实验需要在明文环境中进行训练,并对两个随机图像分量进行推理。P2OD框架采用学习率为0.002,批处理大小为128,迭代60000次,通过最小化分类回归损失得到更新的模型参数。为了衡量P2OD框架的效用,采用召回率和准确率指标对测试数据集进行处理。从图7(b)中,每个类别的平均准确率(AP)可以通过斜线y=x与P-R曲线的平衡点得到。因此,通过对所有类别的AP进行平均,P2OD框架的平均AP (mAP)为80.69%。
图7 测试PO2D框架的精度。
总结
为了保护CAV之间合作检测的图像隐私,本文提出了一个P2OD框架。具体来说,作者设计了一些轻量级的安全计算协议来实现安全的Faster R-CNN模型,这有利于安全地提取与物体相关的特征和边界。两个边缘服务器通过交互式地执行安全的Faster R-CNN模型来进行物体检测。实验结果表明,拟议的P2OD框架可以保护上传图像中的物体分类和有效物体的位置信息,而不影响检测精度。
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh