每周文章分享2023.05.08—2023.05.14简介标题: A Time-Saving Path Planning Scheme for Autonomous Underwater Vehicl 2023-5-13 00:0:32 Author: 网络与安全实验室(查看原文) 阅读量:43 收藏
每周文章分享
2023.05.08—2023.05.14
简
介
标题: A Time-Saving Path Planning Scheme for Autonomous Underwater Vehicles With Complex Underwater Conditions
期刊: IEEE Internet of Things Journal, vol. 10, no. 2, pp. 1001-1013, 15 Jan.15, 2023.
作者: Jiachen Yang; Jiaming Huo; Meng Xi; Jingyi He; Zhengjian Li; Houbing Herbert Song.
分享人: 河海大学——申娅
研究背景
自主水下航行器(AUV)凭借卓越的智能和自主能力,已成为水下物联网(IoUT)系统不可或缺的一部分,在海洋数据收集、环境要素监测和水下资源勘探等军事和民用领域发挥着重要作用。然而,复杂的水下环境给AUV的路径规划带来了巨大的挑战,尤其是洋流,这对时间和能源消耗有着深远的影响。因此设计一种有效的路径规划算法是实现智慧海洋工业的前提。强化学习(RL)由于其能够从与环境的交互中进行自我学习而受到关注,与传统的路径规划方法相比,RL可以在以往样本的基础上动态更新探索策略,并利用当前的状态信息进行决策。重要的是,动态学习能力使RL具有优越的智能,能够适应复杂的洋流条件,训练后的模型在不熟悉的环境中仍然具有应用价值。此外,随着深度学习的普及,利用深度神经网络改进的RL(DRL)可以通过获得强大的拟合能力来处理复杂的状态空间。
关键技术
尽管强化学习在决策方面显示出了极好的潜力,但是由于水下机器人受到不确定性环境的影响,将强化学习应用于AUV路径规划时仍存在一些挑战。主要是由于传感器的探测范围有限,AUV只能获取局部洋流和障碍物信息。因此,水下路径规划算法需要在有限的先验知识下做出决策,比如目标位置和局部信息。针对现有的挑战,本文设计了一种基于近端策略优化的省时水下路径规划方法(UP4O),该方法可以更好地适应信息有限的复杂水下环境。首先,UP4O包含一个信息编码模块,它处理由传感器获得的原始观测结果。连接的输入包含局部障碍物特征、相对于目标的相对位置、速度和洋流信息,便于路径规划算法的实现。其次,为了提高对洋流的利用,本文设计了一个包含26种运动模式的精细动作调整空间。精细动作空间设计可以进一步减小AUV方向与洋流方向的夹角,有效地提高了性能。最后,在多动作空间的基础上,提出了一种利用近端策略优化(PPO)框架的水下路径规划算法,其中Actor网络进行动作选择,Critic网络提供评价值。
该方法的创新和贡献如下:
本文提出了一种应用于UP4O的信息编码模块,通过有效地利用水下环境的局部动态信息,提高了临时决策能力。通过神经网络提取的局部障碍特征,加上相对位置、速度和洋流信息,促进了算法的实现,解决了仅使用位置信息的不足。
2)本文为U4PO设计了一个良好的动作调整空间,其中包括26个离散的运动方向。该多动作空间对洋流的方向更加敏感,因此该方法可以充分利用洋流,减少时间成本,避免障碍。
3)本文首次将PPO算法引入到复杂水下条件下的AUV路径规划中,并精心设计了奖励函数,以加速网络的学习过程。
算法介绍
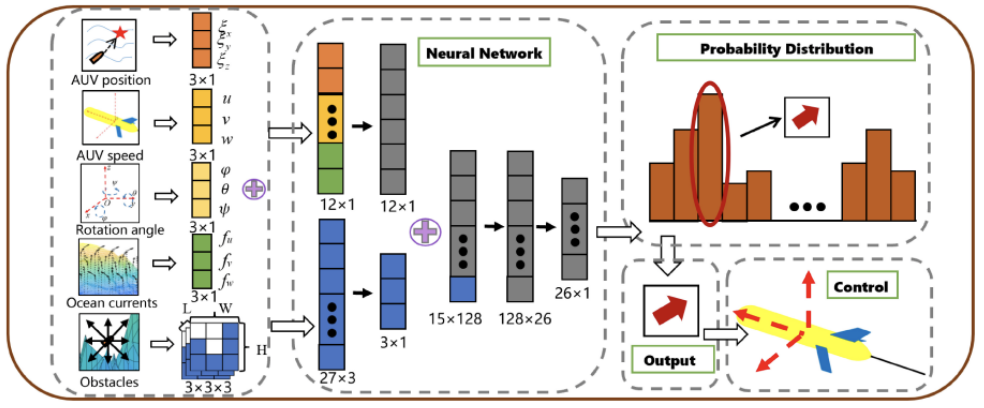
基于近端策略优化的省时水下路径规划方法(UP4O)的架构,如图1所示,包括三个主要组成部分:1)局部信息编码;2)路径规划算法;3)动作空间及奖励函数。
图1 UP4O架构。
(1)局部信息编码
连接到AUV上的传感器可以接收到有限的局部环境信息。对于二维环境,使用单通道和二维阵列H×W来表示周围的环境。在三维环境中,将单通道图像叠加在一起,维度变成H×W×L。障碍物以图像的形式进行描述。它的定义遵循规则,只要网格包含障碍物,就编码为0,否则为1。
然后,对图1中的结果进行重塑,并使用全连通层来提取局部视图的特征。该算法不需要提前知道所有障碍物的位置,因为并不是所有的障碍物都对路径规划有影响。环境信息,包括位置、当前和编码的障碍信息,被连接并应用作为神经网络的输入。这种信息编码促进了AUV关键信息的集成,提高了局部时变信息的利用率。
(2)路径规划算法
在时间步t时与环境交互的代理在在给定的当前状态s(t)下选择一个动作,并根据动态 s(t+1)~P(·|s(t),a(t)) 采样得到下一个状态以及一个奖励r(t+1) = R(s(t),a(t),s(t+1)),重复这个过程,直到达到目标状态。本文定义了策略π来表示从状态到动作上的概率分布的映射,用π(a|s)来表示。对于AUV,状态的维数是一个8维(三维环境中的15维)向量,其中包含相对于目标的当前位置信息、速度矢量、姿态角,洋流信息和编码的障碍信息。在连接的输入通过两个全连接层后,可以得到了每个动作的概率分布。最后的行动是通过根据概率进行抽样来决定。
具体的流程图如图2所示。建立了两个结构相同的actor网络。老actor用于探索和收集样本,新actor使用样本更新网络参数。连接的输入是状态s(t),下一个观测状态是s(t+1)。训练过程分为探索性过程和学习过程。在探索过程中,输入向量通过actor网络,并对动作的概率分布进行采样,得到实际的运动方向。AUV在当前状态下执行此操作,以获得下一刻的状态。该状态变化得到的反馈r(t+1)通过奖励函数计算。当前状态s(t),下一个状态s(t+1),奖励r(t+1),折扣奖励q(t),和动作a(t)作为样本被存储。重复上述过程,直到达到最大的勘探步骤数或目标位置。
由于所有完整轨迹中至少有一个样本都存储在记忆池中,因此折扣奖励将被计算出并插入到相应的样本中。在每一个episode结束后,当内存容量大于指定的值时,网络将会被更新。新actor网络使用剪辑函数来限制目标函数的范围,并防止参数的权重更新范围太大。参数更新之后,新策略的网络参数将被复制到旧策略中,并利用更新后的策略继续进行下一轮的勘探。最终的策略输出一系列的点,它们构成了从指定的起始位置到目标位置的一条节省时间的路径。
图2 UP4O更新机制
(3)动作空间及奖励函数的设计
A、 动作空间设计
假设AUV的速度大小是固定的,且高于洋流的速度大小,即AUV的速度为v_b。当前位置的洋流信息可以通过声学多普勒海流剖面仪(ADCP)感知,其定义为v_c。根据矢量合成定律,可以得到AUV的实际速度。该算法规划了AUV的速度方向。如图3所示,AUV可以在二维环境中向8个方向改变速度v_b,在三维环境中向26个方向改变速度v_b。由于UP4O神经网络的输出维数是固定的,理论上所有方向的选择概率相等,但在实际的训练过程中,本文的方法将通过给出低概率来避免可能导致碰撞的动作。
图3 动作空间
B、 奖励功能设计
奖励函数的设计对RL算法的收敛性有很大的影响。在状态空间和实际动作空间非常复杂的情况下,稀疏奖励很难在有限的步骤下引导代理达到目标。因此,对于考虑洋流的路径规划问题,本文设计了一个普遍适用的奖励函数,它考虑了以下因素:
距离目标的距离奖励(Rd):当AUV接近目标点时,给予50分的固定奖励。由于PPO算法的目标是获得最大的累积奖励,所以目标奖励不应该太大,否则会影响路径的优化。当没有达到目标时,本文使用从目标点到当前位置和下一个位置的欧氏距离来评估动作。
洋流利用程度奖励(Rc):与洋流相关的奖励由实际速度|v_r|与AUV速度|v_b|的比值设定。当目标可到达,且洋流对AUV的运动有积极影响时,实际速度应大于AUV的速度。
安全性奖励(Ro):为了保证路径的安全,当当前位置落在障碍物范围内或路径通过障碍物时,将给予固定的惩罚−20。处罚不应该太大,以防止AUV远离障碍物太远,也不能通过狭窄但安全的区域。随着AUV的移动,惩罚被累积为Ro。
当episode没有结束时,奖励函数被设计为以上三个奖励之和,即:
其中,λd设置1.5,λc设置为1。λd值越大,对距离的奖励发挥的作用就越重要。在确定λd后,加入洋流的影响来优化路径。为了防止代理在环境中往复作用,本文添加了一个衰减因子来加快对目标的搜索:
其中,步骤为当前的总步骤数,在二维和三维环境中,k3分别设置为0.01和0.005。当步数增加时,ζ会对正奖励有明显的衰减效应,正奖励是根据训练过程开始时完整路径上的总步数来设置的。衰减因子解决了主体在空间中可以相互回报以获得奖励的问题,同时使样本在时间顺序上存在差异。一方面,它提示AUV缩短到达目标点的时间,另一方面,它丰富了经验池,使代理能够更充分地学习,并加速了网络的收敛。最后的奖励功能是:
实验结果分析
1. 二维模拟实验
首先验证了UP4O在二维环境中的有效性,这是一个40×40的网格图。训练总次数为1000次,每集最大步长为600次,车辆在静水中的速度为1 m/s。超参数设置为ε = 0.35,学习速率= 0.001,局部视场大小为5×5。本文将决策区间设置为0.5s/像素,并将到达目标的距离阈值考虑为0.5像素(由于洋流的影响,AUV的最终到达位置在给定目标点的0.5像素以内)。将初始速度方向设置为动作空间中最接近当前方向的方向,并根据训练过程进行手动调整。下面的实验比较了这些算法在不同条件下的性能:
不同洋流速度的结果:图4比较了不同强度的洋流。在结果图中,箭头表示当前位置的洋流方向和强度,绿点表示起点(2、36),红星表示目标点(34、6)。在文中使用单环回和双环回来构建洋流环境。参数A为0.7,因此洋流速度在0~0.7 m/s之间,并设置了一些稀疏障碍。将洋流的最大强度与原始强度的比值定义为ratio,并采用不考虑洋流的最短路径进行比较。Ratio被设置为0、0.5和1。显然,洋流下的路径与静态路径的偏差较大。在勘探和更新过程中,代理可以了解策略:当目标可到达时,AUV应利用洋流,节省时间、精力,避免洋流造成的阻力。在实际的海洋环境中,由于洋流的不确定性,强烈的洋流可能会导致AUV的方向发生很大的变化。当AUV采用与钝角相反或相反的方向时,会承受很大的阻力。
图4 二维环境下不同洋流的结果。可以清楚地看到,UP4O规划的路径比最短路径更能利用洋流。绿色和橙色的路径分别在强电流和弱电流中产生。蓝色的路径是最短的路径。(a)单环流。(b)双环流。
不同类型不确定性洋流的结果:为了进一步证明该算法的有效性,本文对洋流的不确定性进行了实验。首先,在图5中测试了不同方法在原始环境中的效果。AUV从(3、35)开始,然后通过路径规划到达(70、5)。考虑到数据的不清晰性,本文在洋流数据中加入高斯噪声来模拟这种情况,以处理仪器的不准确性。本文使用UP4O、IRRT*和流线型方法来进行实验。研究结果见表三,在最终的结果中,UP4O方法可以处理90%的不确定性。IRRT*和基线方法的适应性略差。基线法依赖于观测数据的精度,以选择最合适的正向方向,因此当数据存在不确定性时,其受影响更大。同时,UP4O法的平均时间比基线法少6.5%。
图5 不同方法对洋流影响的结果。
在复杂的障碍物环境下进行的实验结果:为了更好地测试该算法的避障能力,本文使用了一个可能导致局部最优和方块运动的实验环境。为了防止随机抽样造成的不确定性,本文进行了十次重复实验。表五为平均计算结果。同时,为了突出地形的影响,本文只添加了方向缓慢变化的模拟电流,其强度在0~1 m/s之间。图6(a)中的障碍物面积为180 m2。在这种环境下,使用APF方法很容易陷入局部最小困境,使用中提出的改进的APF(IAPF)方法进行实验。与APF方法相比,UP4O的优点是在训练阶段,代理具有随机探索的能力,这不会导致代理停止。同时,通过对样本的学习,对路径进行不断的优化。实验结果表明,IAPF虽然可以生成一个安全的路径,但其路径时间和路径长度最长。在图6(b)中,起点周围有障碍物,只有一小部分区域可以穿越。UP4O方法和IRRT*方法生成路径的成本分别为2.54s和10.98 s。IRRT*算法凭借其随机探索能力,能够在这种环境下规划一条可行的路径,但增加洋流的影响可以增加运行时间。在选择一个新的延伸点时,洋流的影响使IRRT*不能只考虑距离,从而导致曲折的路径。
图6 不同障碍情况下的结果。(a)局部最低值。(b)阻塞的情况。
2. 三维仿真实验
本节介绍了在三维洋流环境下的模拟结果。由于搜索空间的扩展,最大的探索步骤数被调整为2000步。与二维环境相比,在三维空间中的搜索范围更大。传统的算法需要更高的计算机性能,但RL方法可以降低计算的复杂性,依赖于探索与环境的交互、自学习和路径的连续优化。在本节中,本文将比较了UP4O、DQN和IRRT*在三维海洋环境中的性能。然后,本文对局部环境信息编码模块进行了比较实验。
模拟洋流的比较:如图7所示,AUV在规划路径的影响下,从起点(37、2、8)到达目标点(4、36、36)。由于更宽的作用空间和高效的学习机制,路径上的角度变化通常小于90◦,这有利于AUV的控制。在十次重复的测试中,平均路径长度为745.43 m,成本为540.00 s。从垂直的角度可以看出,在三维环境中,该方法仍能在洋流的积极影响下引导AUV。与DQN算法获得的路径相比,根据AUV物理模型提出的动作空间使路径更平滑,动作方向的选择更加灵活。在给定的环境下,当输出26个动作或10个动作(在二维动作空间的基础上添加上下动作)时,DQN很难收敛,因此本文简化了智能体的任务,并将实际动作空间减少到6个方向。由于移动空间的限制,规划路径花费的时间较长。路径长度为984.11 m,成本为791.00 s,比该算法的结果高出约45%。由于行动空间的限制,DQN规划的路径需要在方向变化时克服更大的困难,导致更多的能源消耗。由于空间维数的增加,IRRT*算法的复杂度也增加了。IRRT*在探索路径时受到各种因素的影响,因此它会延迟到达目标点。路径长度为868.51 m,成本为595.52 s,比该算法的结果高出约7%。虽然IRRT*通过椭圆方程约束采样区域,但对于起点和目标点在对角线上的情况,采样范围只能缩小到有限的范围。由于IAPF算法在不规则地形下的结果不稳定,因此在给定的地图上进行多次测试,无法达到目标点,因此无法进行进一步的比较。
图7 结果在三维洋流环境中进行分析。橙色、红色和绿色的路径分别由DQN、UP4O和IRRT*生成。(a)整体视图。(b)垂直视图。
在未知环境中的比较:所有障碍物在x、y方向上随机平移,平移距离在0~4m之间。本文进行了100个实验,并比较了表六中的路径时间、成功率和计算时间。对于路径时间和计算时间,我们只考虑路径能够成功到达目标点的情况。其中一次实验的结果如图13所示。没有局部视图的原始PPO更有可能与障碍发生碰撞,其次是IRRT*。UP4O算法使用在其他环境中训练过的模型,并使用可用的局部和全局信息来进行方向选择。为了保持所得到的局部信息范围一致,IRRT*算法对随机采样范围进行了限制。实验表明,该算法对环境具有一定的适应性,即训练后的模型不仅能处理特定的环境,而且对不断变化的环境有快速的响应。
图8 导致在一个未知的环境中。橙色、红色、绿色的路径分别由PPO、UP4O和IRRT*生成。(a)整体视图。(b)垂直视图。
总结
本文提出了一种基于近端策略优化(UP4O)的水下路径规划方法,该算法可以保证AUV在复杂海洋条件下节省时间和无碰撞路径,使AUV能够在IoUT系统中执行更复杂的任务。在该算法中,首先,使用环境编码模块对局部障碍信息进行编码,并将其与相对位置、速度和局部洋流信息集成,通过连续动作决策生成完整的路径,与传统的动作选择方法相比,该算法提高了局部动态信息的利用率。同时,状态空间更加多样化,使模型具有一定的转移能力。然后,为了提高洋流的利用,本文的方法扩展了作用空间,为AUV提供了多达26种作用模式。这种细粒度的动作可以提高AUV运动的精度,并减少与洋流方向的角度。此外,UP4O引入了RL算法,并提出了一种基于PPO的路径规划算法,其中设计良好的奖励函数有助于学习过程。本文在二维和三维仿真环境中都实现了UP4O和其他算法。实验结果表明,UP4O具有优越性,具有较快的收敛速度和更平滑的路径。特别是在复杂的三维洋流、有限的先验知识和局部信息的条件下,可以找到一条省时、无碰撞的路径,从而缩小了AUV理论研究与实际海洋应用之间的差距。
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh