作者:oliver虽然官方文档记录了 ClickHouse 物化视图很多详细信息,但是使用物化视图还是有很多小细节需要注意,更别说一些最佳实践。本文总结了 ClickHouse 物化视图使用上的各种问 2023-5-9 18:1:26 Author: 腾讯技术工程(查看原文) 阅读量:61 收藏
作者:oliver
虽然官方文档记录了 ClickHouse 物化视图很多详细信息,但是使用物化视图还是有很多小细节需要注意,更别说一些最佳实践。本文总结了 ClickHouse 物化视图使用上的各种问题,并展示三个实际案例。
存储过程与触发器
存储过程:预编译好的一组 SQL 程序,类似 无返回结果 的函数。
强调无返回是为了和真正的 FUNCTION 区分开,这个有返回结果。
触发器:特殊存储过程,监听特定事件自动调用。
数据库查询语言(query language)是数据库管理系统(DBMS)提供给用户和数据库交互的工具,查询语言分为三类 [^1]:
命令式(Imperative):用户控制系统一步步执行操作,计算、获取数据。在计算过程中包含了可变的状态变量。 函数式(Functional):用户调用一系列函数链式执行计算、获取数据。在计算过程中不包含状态变量,无副作用。 声明式(Non-Procedural/Declarative):用户只声明需要的数据,由数据库管理系统实现计算过程并返回数据。
[!TIP] 三类查询语言并不是边界分明 工程中的查询语言,会同时包含多种查询语言的特性。[^2]
人们往往认为 SQL 是用于关系模型(Relational Model)数据库的声明式查询语言,但这个世界并不是非黑即白,声明式语言虽然降低用户学习成本,但数据库承担了检查(词法分析)、翻译(编译)、优化最后执行的过程。但如果业务需要一遍又一遍执行某一段相同的逻辑,每次都要重新走一遍流程,显然不可接受。于是各大关系数据库系统几乎都引入了过程扩展,比如 PG 使用的 PL/pgSQL[^3],它包含变量定义、条件控制和循环等等过程式语言的元素。
那么引入本节的主角:存储过程(Stored Procedure),预先编译好的一段逻辑(用过程语言),可以大大加快执行速度。
而触发器(Trigger)则是一种特殊的存储过程,它监听某些数据库事件,可以在事件发生前/中/后调用。[^4]
从事件类型上看,触发器分为:
DDL 触发器 DML 触发器
从触发动作上看 [^5],触发器分为:
事前、事后触发器(BEFORE、AFTER) 替换触发器(INSTEAD OF)
那么触发器有什么业务场景呢?举个最简单的例子,记录某张表的审计日志(Audit Log),把所有 DML 操作都通过触发器记录下来。
ClickHouse 物化视图
ClickHouse 作为关系型 OLAP(OnLine Analytical Processing)数据库,很遗憾不支持存储过程。[^6]
[!TIP] ClickHouse 存储过程的实现状况 在 2023 年 Roadmap 中 Experimental features and research 部分可以看到 refreshable materialized views,有生之年
但非常有意思的是,ClickHouse 提供了物化视图(Materialized View)的特殊功能,在功能上相当于 AFTER INSERT 触发器,物化视图仍然使用 声明式 SQL 定义计算逻辑。
源码阅读
[!TIP] 提示 可以直接跳到 总结 部分。
[!TIP] ClickHouse 版本 本文源码阅读基于 ClickHouse 22.3 版本
StorageMaterializedView
首先看到物化视图的类声明 src/Storages/StorageMaterializedView.h:
class StorageMaterializedView final : public IStorage, WithMutableContext
{
public:
...
private:
/// Will be initialized in constructor
StorageID target_table_id = StorageID::createEmpty(); bool has_inner_table = false;
...
}
可以看到物化视图继承自 IStorage 类,从它的类注释中可以看到它管理的功能。物化视图和 StorageMerge 一样都继承自这个管理数据存储的类,作为一个视图,莫非也有实际存储?此外,物化视图用 target_table_id 存储了别的表的 id。接下来看看 IStorage 的类注解:
/** Storage. Describes the table. Responsible for
* - storage of the table data;
* - the definition in which files (or not in files) the data is stored;
* - data lookups and appends;
* - data storage structure (compression, etc.)
* - concurrent access to data (locks, etc.)
*/
如果读物化视图会发生什么?跳转到重载 IStorage 的 StorageMaterializedView::read 方法定义:
void StorageMaterializedView::read(
...)
{
auto storage = getTargetTable();
...
storage->read(query_plan, column_names, target_storage_snapshot, query_info, local_context, processed_stage, max_block_size, num_streams);
...
}
以及 StorageMaterializedView::getTargetTable 方法定义:
StoragePtr StorageMaterializedView::getTargetTable() const
{
checkStackSize();
return DatabaseCatalog::instance().getTable(target_table_id, getContext());
}
读操作是对 target_table_id 对应的表进行的,那么就清晰了,物化视图并不会存储数据,会将查询重定向到目标表。
做个实验简单验证:
create table test( time DateTime) Engine=Memory();
create table source(time DateTime) Engine=Memory();
create materialized view mv_test to test as select time from source;
insert into table source values(now());select * from test;
┌────────────────time─┐
│ 2023-02-25 18:51:41 │
└─────────────────────┘
select * from mv_test;
┌────────────────time─┐
│ 2023-02-25 18:51:41 │
└─────────────────────┘
explain select * from test;
┌─explain───────────────────────────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ SettingQuotaAndLimits (Set limits and quota after reading from storage) │
│ ReadFromStorage (Memory) │
└───────────────────────────────────────────────────────────────────────────┘
explain select * from mv_test;
┌─explain───────────────────────────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ SettingQuotaAndLimits (Set limits and quota after reading from storage) │
│ SettingQuotaAndLimits (Lock destination table for MaterializedView) │
│ ReadFromStorage (Memory) │
└───────────────────────────────────────────────────────────────────────────┘
注意 Lock destination table for MaterializedView,符合猜测。
接着写操作会发生什么?猜测也会重定向到目标表,看看 StorageMaterializedView::write 方法的定义:
SinkToStoragePtr StorageMaterializedView::write(...)
{
auto storage = getTargetTable();
...
auto sink = storage->write(query, metadata_snapshot, local_context);
...
}
再做个小实验验证:
insert into table mv_test values(now());select * from test;
┌────────────────time─┐
│ 2023-02-25 18:51:41 │
└─────────────────────┘
┌────────────────time─┐
│ 2023-02-25 19:11:20 │
└─────────────────────┘
符合猜测。
解答完疑惑,回到正常阅读顺序来,接下来阅读构造器的代码 src/Storages/StorageMaterializedView.cpp:
StorageMaterializedView::StorageMaterializedView(
const StorageID & table_id_,
ContextPtr local_context,
const ASTCreateQuery & query,
const ColumnsDescription & columns_,
bool attach_,
const String & comment)
: IStorage(table_id_), WithMutableContext(local_context->getGlobalContext())
{
...
/// If the destination table is not set, use inner table
has_inner_table = query.to_table_id.empty(); // 出现了新概念 inner table
if (has_inner_table && !query.storage) // 创建物化视图时,要么有 ENGINE 使用 inner table,要么用 TO 使用外部表
throw Exception(
"You must specify where to save results of a MaterializedView query: either ENGINE or an existing table in a TO clause",
ErrorCodes::INCORRECT_QUERY); if (query.select->list_of_selects->children.size() != 1)
throw Exception("UNION is not supported for MATERIALIZED VIEW", ErrorCodes::QUERY_IS_NOT_SUPPORTED_IN_MATERIALIZED_VIEW);
...
// 设置 to_table_id
if (!has_inner_table)
{
target_table_id = query.to_table_id;
}
else if (attach_)
{
/// If there is an ATTACH request, then the internal table must already be created.
target_table_id = StorageID(getStorageID().database_name, generateInnerTableName(getStorageID()), query.to_inner_uuid);
}
else // 创建inner table
{
/// We will create a query to create an internal table.
...
target_table_id = DatabaseCatalog::instance().getTable({manual_create_query->getDatabase(), manual_create_query->getTable()}, getContext())->getStorageID(); // 看来 ClickHouse 有个全局表注册表
}
}
可以看到:
物化视图创建时需要指定目标表,不然会自己创建 inner 表 物化视图不能使用 UNIONClickHouse 系统有个表的“注册表”,维护系统所有表的 id- 实例映射
IInterpreter、InterpreterInsertQuery
那么下一个问题,对原始表插入数据,数据又怎么经过物化视图跑到目标表的?
首先关注查询类 src/Interpreters/IInterpreter.h:
/** Interpreters interface for different queries.
*/
class IInterpreter
{
public:
/** For queries that return a result (SELECT and similar), sets in BlockIO a stream from which you can read this result.
* For queries that receive data (INSERT), sets a thread in BlockIO where you can write data.
* For queries that do not require data and return nothing, BlockIO will be empty.
*/
virtual BlockIO execute() = 0;
...
}
当插入(INSERT)数据时,系统会调用 IInterpreter 的子类 src/Interpreters/InterpreterInsertQuery.cpp 处理查询,先看到它的声明:
/** Interprets the INSERT query.
*/
class InterpreterInsertQuery : public IInterpreter, WithContext
{
public:
...
/** Prepare a request for execution. Return block streams
* - the stream into which you can write data to execute the query, if INSERT;
* - the stream from which you can read the result of the query, if SELECT and similar;
* Or nothing if the request INSERT SELECT (self-sufficient query - does not accept the input data, does not return the result).
*/
BlockIO execute() override;
...
private
...
Chain buildChainImpl(
const StoragePtr & table,
const StorageMetadataPtr & metadata_snapshot,
const Block & query_sample_block,
ThreadStatusesHolderPtr thread_status_holder,
std::atomic_uint64_t * elapsed_counter_ms);
};
继续看它的定义(只看 INSERT 分支):
BlockIO InterpreterInsertQuery::execute()
{
...
StoragePtr table = getTable(query);
... StoragePtr inner_table;
if (const auto * mv = dynamic_cast<const StorageMaterializedView *>(table.get())) // 如果 insert query 指向的表是 StorageMaterializedView,目标表取出放到 inner_table 变量中
inner_table = mv->getTargetTable();
...
std::vector<Chain> out_chains;
if (!distributed_pipeline || query.watch)
{
size_t out_streams_size = 1;
if (query.select) // 处理 INSERT SELECT,忽略
{
...
}
else if (query.watch) // 处理 LIVE VIEW 的 WATCH 语句,直接忽略即可
{
...
}
for (size_t i = 0; i < out_streams_size; ++i)
{
auto out = buildChainImpl(table, metadata_snapshot, query_sample_block, nullptr, nullptr); // 构建 chain,重要!!!
out_chains.emplace_back(std::move(out));
}
}
BlockIO res;
/// What type of query: INSERT or INSERT SELECT or INSERT WATCH?
if (distributed_pipeline)
{
res.pipeline = std::move(*distributed_pipeline);
}
else if (query.select || query.watch)
{
... // 直接忽略
}
else // 关注这个分支,query 是 INSERT 时
{
res.pipeline = QueryPipeline(std::move(out_chains.at(0))); // 将 chain 第一个元素构造返回 BlockIO 的 pushing pipeline
res.pipeline.setNumThreads(std::min<size_t>(res.pipeline.getNumThreads(), settings.max_threads)); // 设置 query 的配置
if (query.hasInlinedData() && !async_insert)
{ // 也就是 INSERT 语句带了 VALUES (...),可以直接从语句中拿到要插入的数据
/// can execute without additional data
auto pipe = getSourceFromASTInsertQuery(query_ptr, true, query_sample_block, getContext(), nullptr);
res.pipeline.complete(std::move(pipe));
}
}
res.pipeline.addResources(std::move(resources));
res.pipeline.addStorageHolder(table); // 将 query 的目标表放入 pipeline 资源列表
if (inner_table) // 如果有物化视图
res.pipeline.addStorageHolder(inner_table); // 把物化视图的目标表也放到 pipeline 的资源列表
return res;
}
可以看到方法内调用了 InterpreterInsertQuery::buildChainImpl,接着看这个方法的定义:
Chain InterpreterInsertQuery::buildChainImpl(
const StoragePtr & table,
const StorageMetadataPtr & metadata_snapshot,
const Block & query_sample_block,
ThreadStatusesHolderPtr thread_status_holder,
std::atomic_uint64_t * elapsed_counter_ms)
{
... /// We create a pipeline of several streams, into which we will write data.
Chain out;
/// Keep a reference to the context to make sure it stays alive until the chain is executed and destroyed
out.addInterpreterContext(context_ptr);
/// NOTE: we explicitly ignore bound materialized views when inserting into Kafka Storage.
/// Otherwise we'll get duplicates when MV reads same rows again from Kafka.
if (table->noPushingToViews() && !no_destination) // table->noPushingToViews() 用于禁止物化视图插入数据到 KafkaEngine
{
auto sink = table->write(query_ptr, metadata_snapshot, context_ptr);
sink->setRuntimeData(thread_status, elapsed_counter_ms);
out.addSource(std::move(sink));
}
else // 构建物化视图插入 pushingToViewChain,重点!!!
{
out = buildPushingToViewsChain(table, metadata_snapshot, context_ptr, query_ptr, no_destination, thread_status_holder, elapsed_counter_ms);
}
...
return out;
}
Chain 相关
接着来到文件 src/Processors/Transforms/buildPushingToViewsChain.cpp:
Chain buildPushingToViewsChain(
const StoragePtr & storage,
const StorageMetadataPtr & metadata_snapshot,
ContextPtr context,
const ASTPtr & query_ptr,
bool no_destination,
ThreadStatusesHolderPtr thread_status_holder,
std::atomic_uint64_t * elapsed_counter_ms,
const Block & live_view_header)
{
... auto table_id = storage->getStorageID();
Dependencies dependencies = DatabaseCatalog::instance().getDependencies(table_id); // 重点,通过 table_id,拿到“依赖“这个表的 dependencies
/// We need special context for materialized views insertions
ContextMutablePtr select_context;
ContextMutablePtr insert_context;
ViewsDataPtr views_data;
if (!dependencies.empty())
{
... // 把query的各种上下文拆出
}
std::vector<Chain> chains;
for (const auto & database_table : dependencies)
{
auto dependent_table = DatabaseCatalog::instance().getTable(database_table, context);
auto dependent_metadata_snapshot = dependent_table->getInMemoryMetadataPtr();
ASTPtr query;
Chain out;
...
if (auto * materialized_view = dynamic_cast<StorageMaterializedView *>(dependent_table.get())) // 依赖关系是 MATERIALIZED VIEW
{
type = QueryViewsLogElement::ViewType::MATERIALIZED;
result_chain.addTableLock(materialized_view->lockForShare(context->getInitialQueryId(), context->getSettingsRef().lock_acquire_timeout));
StoragePtr inner_table = materialized_view->getTargetTable(); // 拿到物化视图的目标表
auto inner_table_id = inner_table->getStorageID();
auto inner_metadata_snapshot = inner_table->getInMemoryMetadataPtr();
query = dependent_metadata_snapshot->getSelectQuery().inner_query;
target_name = inner_table_id.getFullTableName();
/// Get list of columns we get from select query.
auto header = InterpreterSelectQuery(query, select_context, SelectQueryOptions().analyze())
.getSampleBlock();
/// Insert only columns returned by select.
Names insert_columns;
const auto & inner_table_columns = inner_metadata_snapshot->getColumns();
for (const auto & column : header)
{
/// But skip columns which storage doesn't have.
if (inner_table_columns.hasPhysical(column.name)) // 注意,是通过列名匹配的,而不是位置,这在使用物化视图时很容易犯错
insert_columns.emplace_back(column.name);
}
InterpreterInsertQuery interpreter(nullptr, insert_context, false, false, false); // 将物化视图的插入逻辑也作为 InterpreterInsertQuery 处理
out = interpreter.buildChain(inner_table, inner_metadata_snapshot, insert_columns, thread_status_holder, view_counter_ms);
out.addStorageHolder(dependent_table);
out.addStorageHolder(inner_table);
}
else if (auto * live_view = dynamic_cast<StorageLiveView *>(dependent_table.get())) // 依赖关系是 LIVE VIEW,忽略
{
...
}
else if (auto * window_view = dynamic_cast<StorageWindowView *>(dependent_table.get())) // 依赖关系是 WINDOW VIEW,忽略
{
...
}
else
out = buildPushingToViewsChain(
dependent_table, dependent_metadata_snapshot, insert_context, ASTPtr(), false, thread_status_holder, view_counter_ms); // 我理解这里是级联物化视图分支
views_data->views.emplace_back(ViewRuntimeData{ //-V614
std::move(query),
out.getInputHeader(),
database_table,
nullptr,
std::move(runtime_stats)});
if (type == QueryViewsLogElement::ViewType::MATERIALIZED)
{
auto executing_inner_query = std::make_shared<ExecutingInnerQueryFromViewTransform>(
storage_header, views_data->views.back(), views_data);
executing_inner_query->setRuntimeData(view_thread_status, view_counter_ms);
out.addSource(std::move(executing_inner_query));
}
chains.emplace_back(std::move(out));
/// Add the view to the query access info so it can appear in system.query_log
if (!no_destination)
{
context->getQueryContext()->addQueryAccessInfo(
backQuoteIfNeed(database_table.getDatabaseName()), views_data->views.back().runtime_stats->target_name, {}, "", database_table.getFullTableName());
}
}
...
if (auto * live_view = dynamic_cast<StorageLiveView *>(storage.get()))
{
...
}
else if (auto * window_view = dynamic_cast<StorageWindowView *>(storage.get()))
{
...
}
/// Do not push to destination table if the flag is set
else if (!no_destination) // 物化视图写入逻辑
{
auto sink = storage->write(query_ptr, metadata_snapshot, context); // 注意,第一个参数是传入的 query_ptr,也就是说物化视图的数据同样直接来自于查询,而不是依赖表
metadata_snapshot->check(sink->getHeader().getColumnsWithTypeAndName());
sink->setRuntimeData(thread_status, elapsed_counter_ms);
result_chain.addSource(std::move(sink));
}
...
return result_chain;
}
注意到 DatabaseCatalog::instance().getDependencies(table_id)(在文件 src/Interpreters/DatabaseCatalog.cpp)获取“依赖”在这个表的关系 dependencies,查看源码:
Dependencies DatabaseCatalog::getDependencies(const StorageID & from) const
{
std::lock_guard lock{databases_mutex};
auto iter = view_dependencies.find({from.getDatabaseName(), from.getTableName()});
if (iter == view_dependencies.end())
return {};
return Dependencies(iter->second.begin(), iter->second.end()); // 查找到的 dependencies set 按照顺序塞入 vector 返回
}
在头文件声明了 view_dependencies 和它的类型:
/// Table -> set of table-views that make SELECT from it.
using ViewDependencies = std::map<StorageID, std::set<StorageID>>;
using Dependencies = std::vector<StorageID>;
...
/// For some reason Context is required to get Storage from Database object
class DatabaseCatalog : boost::noncopyable, WithMutableContext
{
public:
...
private:
ViewDependencies view_dependencies TSA_GUARDED_BY(databases_mutex);
}
这几个函数的参数是 StorageID(在文件 src/Interpreters/StorageID.h),可以看到它的声明:
struct StorageID
{
String database_name;
String table_name;
UUID uuid = UUIDHelpers::Nil;
...
private:
...
};
由于 ViewDependencies 这个 map 的 value 是 std::set,在 cpp 中 std::set 的元素会用 std::set::key_comp 方法来排序 [^7],因此物化视图的处理将按照字母顺序。
总结
可以看到:
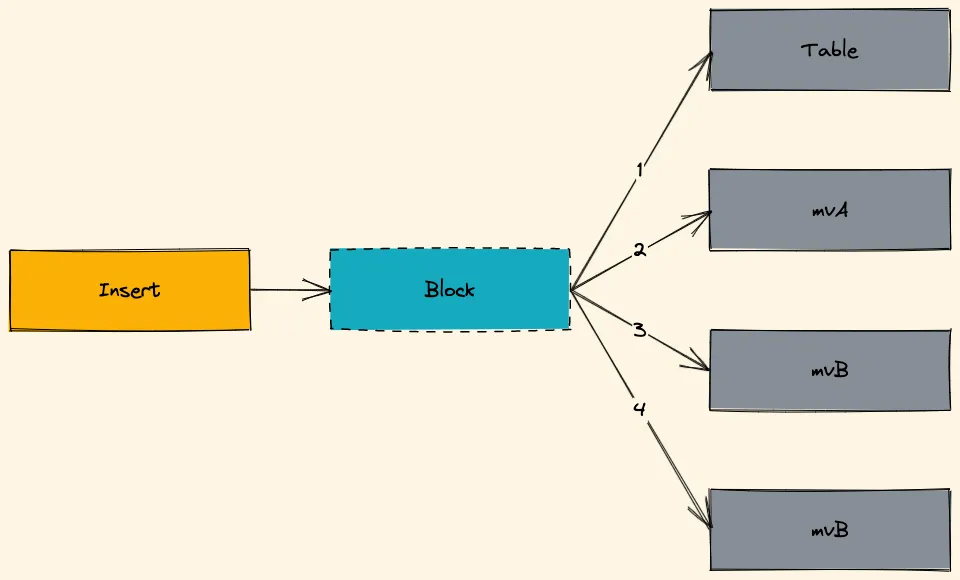
数据插入时,先处理原始表插入,再处理物化视图的插入。
![[mv-insert-internally.excalidraw]]
有多个物化视图时,按照字母顺序依次处理。
当设置 parallel_view_processing=1时,物化视图并行处理物化视图不会读取源表数据,而是插入时同一份数据依次插入源表、目标表。
物化视图相当于 AFTER INSERT TRIGGER,对于目标表而言,不存在任何视图概念,它只看到一个个 INSERT 查询。
物化视图可以级联。
FAQ
前文通过源码阅读了解了物化视图的底层逻辑,接下来从使用者的角度继续分析物化视图。
物化视图使用场景
数据预聚合/数据增量聚合 数据预处理/ET(Extract-Transform) 以另一组 ORDER BY 存储数据(模拟方向索引) KafkaEngine
[!TIP] 真正的方向索引 ClickHouse 将在 23.1 引入真正的反向索引能力。[^8]
创建物化视图
先看到官方文档的 SQL:
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db.]table_name [ON CLUSTER] [TO[db.]name] [ENGINE = engine] [POPULATE] AS SELECT ...
有两种方式创建物化视图:
有 ENGINE关键词,ClickHouse 将创建隐式表(Implicit Table)作为目标表有 TO关键词,需要用户预先创建目标表
使用 ENGINE 时,ClickHouse 除了创建物化视图,还会创建一个名为 .inner.物化视图名 的隐式表,隐式表其实就是正常的表只不过它以 . 开头,直接使用它需要反引号/双引号括起来。
POPULATE 只有使用隐式表时生效,它会在 ClickHouse 创建物化视图后,将原始表 所有 的历史数据全部处理写入隐式表。如果原始表有海量数据,将使用大量资源、持续较长时间。
[!TIP]
TO如何插入历史数据 手动执行INSERT ... SELECT,最好按照_partition_id、_part虚拟列分片插入。[^9]
这两种方式有使用上的优劣区别:
| 能力 | 隐式表 | 外部表 |
|---|---|---|
| 查询优化 | 查询物化视图时,optimize_move_to_prewhere 优化异常 [^10]。想要最佳查询性能必须查询隐式表 | |
| populate | 无法使用 | |
| 删除物化视图 | 隐式表也会被删除 | 不会影响外部表 |
因此建议使用 TO 创建物化视图。
[!ERROR] 物化视图不会读源表 物化视图和原始表磁盘上的数据没有半点关系,换句话说:
原始表是 SummingMergeTree、ReplacingMergeTree等等时,物化视图不会“看”到处理后的数据在原始表上的 DML 不会影响到物化视图和目标表
[!ERROR] 物化视图使用列名插入数据 物化视图通过列名插入数据而不是位置
CREATE MATERIALIZED VIEW mv (
a Int64,
d Date,
cnt Int64
) ENGINE = SummingMergeTree
PARTITION BY toYYYYMM(d)
ORDER BY (a,d)
POPULATE
AS
SELECT
a,
d,
count() AS cnt -- 一定要注意 AS cnt
FROM source GROUP BY a, d;
数据副本碰上物化视图
使用 ReplicatedMergeTree 家族的 Engine 和物化视图时,物化视图还能正常工作吗?
不同 shard 之间不用考虑,因为数据不相同,这里只考虑同一个 shard 不同 replica 的情况:
需要注意,插入只会发生在一个节点,所以作为插入触发器的物化视图也只会在插入发生的节点被触发,接着由 Replicated 的同步机制把物化视图目标表的数据同步到另一个 Replica。
所以没问题~
分布式表碰上物化视图
现在假设一个场景,有 4 个 node,2 个 shard、2 个 replica,每个节点有个 source 本地表和 dest 本地表,并注册了 source_dist 和 dest_dist 两个分布式表。我想要实现插入 source 的数据都进入到 dest,应该如何设计物化视图?
排列组合一下,有下面四种方式:
source -> dest source_dist -> dest_dist source -> dest_dist source_dist -> dest
答案是前三种可以满足要求。但首推第一种,没有网络开销,数据在节点内部处理、存储。第二种、第三种只有在需要数据被打散分布时使用,比如所 source 表根据用户 id(user_id)分 shard,结果表想通过设备 id(device_id)分 shard。
第四种会导致所有 source 的数据都出现在每个节点,一般而言是错误使用。
Join 碰上物化视图
绝对避免在物化视图中使用 join,ClickHouse 使用 HashJoin,插入的每个 Block 都会导致物化视图创建一个 hash 表,最终导致插入又重又慢。
可以通过可复用的数据结构实现 join 的能力 [^11]:
物化视图级联
物化视图可以通过级联(Cascade)串起来:
需要注意的是,级联只能是不同物化视图的 计算逻辑,比如第一个物化视图 GROUP BY,第二个物化视图 FILTER,与目标表没有任何关系。设计物化视图级联时,大可以把前面物化视图的目标表当作 Null 表,避免干扰。
PG 物化视图对比
介绍完 ClickHouse 物化视图,当然要对比下传统 OLTP 关系型数据库的物化视图功能。
| 能力 | ClickHouse 物化视图 | PG 物化视图 |
|---|---|---|
| 存储数据 | 不存储数据,对物化视图的插入、查询会被重定向到目标表 | 会存储数据 |
| 查询优化 | 对物化视图的查询不会被优化(WHERE-TO-PREWHERE) | 充分利用 PG 规则系统的查询重写能力 [^12],和查询普通表性能相当 |
| 更新方式 | 流式更新,源表插入实时由物化视图处理 | 手动更新,需要手动执行 REFRESH MATERIALIZED VIEW 更新物化视图;分为增量更新和全量更新 [^13] |
| 使用场景 | 实时性要求较高的场合;更偏向于系统内部的实时 ETL 能力 | 对数据实时性要求不高的场合 |
物化视图案例
下文给出几个物化视图的真实案例。
KafkaEngine
KakfaEngine 因为很难错误调试被人诟病,比如在 21.6 版本之前,KafkaEngine 解析数据出错只能通过 input_format_skip_unknown_fields 设置跳过 N 条错误消息,然后在系统日志中查询记录:
select * from system.text_log where logger_name like '%Kafka%'
但这个 PR 被合入后有了新的错误检查方法,给 KafkaEngine 新增一个配置 kafka_handle_error_mode='stream',每条消息将带上 _error 和 _raw_message 两个虚拟列。
SQL 代码如下 [^14]:
CREATE TABLE default.kafka_engine
(
`i` Int64,
`s` String
)
ENGINE = Kafka
SETTINGS kafka_broker_list = 'kafka:9092'
kafka_topic_list = 'topic',
kafka_group_name = 'clickhouse',
kafka_format = 'JSONEachRow',
kafka_handle_error_mode='stream';CREATE MATERIALIZED VIEW default.kafka_data
(
`i` Int64,
`s` String
)
ENGINE = MergeTree
ORDER BY (`i`)
AS
SELECT
`i`,
`s`
FROM default.kafka_engine
WHERE length(_error) = 0
CREATE MATERIALIZED VIEW default.kafka_errors
(
`topic` String,
`partition` Int64,
`offset` Int64,
`raw` String,
`error` String
)
ENGINE = MergeTree
ORDER BY (topic, partition, offset)
SETTINGS index_granularity = 8192 AS
SELECT
_topic AS topic,
_partition AS partition,
_offset AS offset,
_raw_message AS raw,
_error AS error
FROM default.kafka_engine
WHERE length(_error) > 0
让 JDBC 支持插入二维数组
JDBC 无法支持二维数组,但是许多业务的的确确需要用到二维数组,除了换语言还可以使用物化视图。
创建一个 Null 表使用 JDBC 支持的数据格式 String 传输嵌套结构的字符串,然后通过物化视图解析插入到最终表:
CREATE TABLE IF NOT EXISTS entry (
json_str String
)ENGINE = Null;CREATE TABLE IF NOT EXISTS dest (
two_diemnsional_array Array(Array(String))
)ENGINE = MergeTree()
ORDER BY tuple();
CREATE MATERIALIZED VIEW mv_dest TO dest
AS
SELECT
JSONExtract(json_str, 'Array(Array(String))') as two_diemnsional_array
FROM entry;
多维表增量预聚合
ClickHouse 作为 OLAP 数据库经常使用多维表、大宽表的 schema,可是原始表直接用于多维分析,需要存储的数据量过大,自然就想到用预聚合减少数据量。
物化视图中的 GROUP BY 是针对每一个 Batch 而言的(流处理),当时间纬度横跨很大,单单一个物化视图恐怕不能很好地将数据聚合。于是可以考虑使用 SummingMergeTree/AggregatingMergeTree 实现先插入后增量聚合。
除此之外,对于高基数字段,比如用户 id(user_id)、设备 id(device_id)这一类列,需要聚合时有不同场景的考量:
若只用于统计基数 精确统计:bitmap 概率统计: uniqState+uniqMerge需要保留每一个元素用于 filter:set/array
资源使用当然就是:概率统计基数 < 精确统计基数 << 保留每个元素
下面给出一个例子,高基数字段只用于统计基数,可以接受误差:
CREATE TABLE IF NOT EXISTS event -- 原始表
(
`app_id` LowCardinality(String) CODEC(ZSTD(9)),
`time` Int64 CODEC(Delta, ZSTD(9)),
`user_id` String CODEC(Delta, ZSTD(9)),
`device_id` String CODEC(Delta, ZSTD(9)),
`d1` String CODEC(ZSTD(9)),
`d2` String CODEC(ZSTD(9)),
`d3` String CODEC(ZSTD(9)),
`d4` String CODEC(ZSTD(9)),
`d5` String CODEC(ZSTD(9)),
`d6` String CODEC(ZSTD(9)),
`v1` Int64 CODEC(T64, ZSTD(9)),
`v2` Int64 CODEC(T64, ZSTD(9)),
`v3` Int64 CODEC(T64, ZSTD(9)),
`v4` Int64 CODEC(T64, ZSTD(9)),
`v5` Int64 CODEC(T64, ZSTD(9)),
`v6` Int64 CODEC(T64, ZSTD(9))
)ENGINE = MergeTree()
PARTITION BY intDiv(time, 2592000000)
ORDER BY (app_id, time)
TTL toDate(intDiv(time, 1000)) + toIntervalMonth(1)
SETTINGS index_granularity = 8192, ttl_only_drop_parts = 1, use_minimalistic_part_header_in_zookeeper = 1;CREATE TABLE IF NOT EXISTS event_agg_5min
(
`app_id` LowCardinality(String) CODEC(ZSTD(9)),
`time` Int64 CODEC(Delta, ZSTD(9)),
`user_cnt` AggregateFunction(uniq, String) CODEC(ZSTD(9)),
`device_cnt` AggregateFunction(uniq, String) CODEC(ZSTD(9)),
`cnt` SimpleAggregateFunction(sum, Int64) CODEC(T64, ZSTD(9)),
`d1` String CODEC(ZSTD(9)),
`d2` String CODEC(ZSTD(9)),
`d3` String CODEC(ZSTD(9)),
`d4` String CODEC(ZSTD(9)),
`d5` String CODEC(ZSTD(9)),
`d6` String CODEC(ZSTD(9)),
`v1` SimpleAggregateFunction(sum, Int64) CODEC(T64, ZSTD(9)),
`v2` SimpleAggregateFunction(sum, Int64) CODEC(T64, ZSTD(9)),
`v3` SimpleAggregateFunction(sum, Int64) CODEC(T64, ZSTD(9)),
`v4` SimpleAggregateFunction(sum, Int64) CODEC(T64, ZSTD(9)),
`v5` SimpleAggregateFunction(sum, Int64) CODEC(T64, ZSTD(9)),
`v6` SimpleAggregateFunction(sum, Int64) CODEC(T64, ZSTD(9))
)
ENGINE = AggregatingMergeTree() -- 落盘后增量预聚合
PARTITION BY intDiv(time, 2592000000)
PRIMARY KEY (app_id, time)
ORDER BY (app_id, time, d1, d2, d3, d4, d5, d6) -- ORDER BY 需要包含所有“标签”列
TTL toDate(intDiv(time, 1000)) + toIntervalMonth(1)
SETTINGS index_granularity = 8192, ttl_only_drop_parts = 1, use_minimalistic_part_header_in_zookeeper = 1;
CREATE MATERIALIZED VIEW IF NOT EXISTS mv_event_agg_5min TO event_agg_5min AS
SELECT
app_id,
intDiv(entrance_time, 300000) * 300000 AS entrance_time, -- 5 分钟聚合
uniqState(user_id) AS user_cnt, -- AggregateFunction使用 -State 聚合
uniqState(device_id) AS device_cnt, -- 注意 AS 重命名
count(*) AS cnt,
d1,
d2,
d3,
d4,
d5,
d6,
sum(v1) as v1, -- SimpleAggregateFunction 直接使用聚合函数
sum(v2) as v2,
sum(v3) as v3,
sum(v4) as v4,
sum(v5) as v5,
sum(v6) as v6
FROM event
GROUP BY -- 单个 Block 内预聚合
app_id,
category,
d1,
d2,
d3,
d4,
d5,
d6;
参考:
[1]: Abraham Silberschatz, Henry F. Korth, and S. Sudarshan, Database System Concepts, Seventh edition (New York, NY: McGraw-Hill, 2020). P47
[2]: https://en.wikipedia.org/wiki/SQL
[3]: https://en.wikipedia.org/wiki/PL/pgSQL
[4]: https://learn.microsoft.com/en-us/sql/t-sql/statements/create-trigger-transact-sql?view=sql-server-ver16
[5]: https://www.postgresql.org/docs/current/sql-createtrigger.html
[6]: https://dbdb.io/db/clickhouse
[7]: https://cplusplus.com/reference/set/set/
[8]:https://clickhouse.com/blog/clickhouse-search-with-inverted-indices
[9]:https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/mergetree/#virtual-columns
[10]: https://github.com/ClickHouse/ClickHouse/issues/11470
[11]: Denis Zhuravlev and Denny Crane, “Everything You Should Know about Materialized Views.,” n.d.
[12]: https://www.postgresql.org/docs/9.4/rule-system.html
[^13]:https://www.postgresql.org/docs/9.4/sql-refreshmaterializedview.html [^14]:https://kb.altinity.com/altinity-kb-integrations/altinity-kb-kafka/error-handling/
如有侵权请联系:admin#unsafe.sh